Mastering Visual Narrative Transitions Through Advanced Generative Video Platforms
In the modern digital landscape, the saturation of static content has led to a significant decrease in audience retention rates. Creators and brands often find that even the most stunning photography can feel stagnant when placed alongside high-energy video feeds. This creates a psychological gap where the viewer’s brain recognizes a lack of “life” in the content, leading to a quick loss of interest. The fundamental problem is that high-quality video production has traditionally required a prohibitive amount of time, equipment, and technical expertise. Utilizing Image to Video AI offers a strategic intervention, allowing users to convert their existing high-resolution stills into dynamic assets that command attention without the traditional overhead of a film set.
In my observation, the transition from being a photographer to becoming a “generative director” is a defining shift for modern storytellers. This process involves more than just adding movement; it is about interpreting the latent potential within a still frame. When you look at a photo of a forest, the AI sees the potential for wind in the leaves; in a photo of a city street, it sees the potential for light trails and bustling crowds. This ability to “extrapolate” reality is what makes the current generation of tools so transformative for content creators across every industry, from e-commerce to education.
Advanced Model Integration For Superior Cinematic Motion Quality
The technical foundation of premium motion synthesis relies on a sophisticated hierarchy of AI models that work in tandem. Platforms that lead the industry integrate powerful engines such as Sora 2, Veo 3.1, and ByteDance’s Seedance 2.0. Each of these models is specialized for different visual tasks. For example, Seedance 2.0 is particularly effective at “multi-referencing,” meaning it can look at an image, a text prompt, and even an audio cue simultaneously to ensure the resulting video is perfectly aligned with the user’s intent. In my testing, this results in an Image to Video output that feels grounded in real-world physics rather than looking like a digital distortion.
One of the most impressive technical aspects of these systems is their ability to handle environmental consistency. When a camera tilts or zooms, the AI must reinvent parts of the scene that were not visible in the original photo. This requires a high level of “spatial intelligence.” My observation is that the latest versions of these models have significantly improved their ability to maintain consistent lighting and shadows even as the perspective shifts. This level of fidelity is crucial for professional marketers who need to ensure that their product videos look as polished and realistic as possible, maintaining brand trust through visual excellence.
Navigating The Technical nuances Of Camera Control And Motion Direction
To get the most out of a generative platform, a creator must understand the nuances of camera motion controls. Most professional-grade systems now allow for explicit direction, such as panning left to right, zooming into a subject, or tilting the camera up to reveal a sky. This level of control is what separates a simple “animated GIF” style output from a true cinematic clip. In my personal observation, the use of a subtle “rotation” or “tilt” can add a sense of handheld realism to a shot, making the viewer feel as though they are actually standing in the scene rather than just looking at a screen.
However, a professional approach also requires an understanding of the tool’s limitations. Currently, the most stable generations are around five seconds in length. While this may seem short, it is the standard duration for high-impact social media segments and ad hooks. It is also important to note that the AI’s performance is highly dependent on the “prompt engineering” provided by the user. A prompt that is too simple may lack character, while one that is overly complex may confuse the model’s physics engine. Finding the “sweet spot” of descriptive language is a skill that distinguishes expert users from beginners in the generative space.

Official Workflow For Achieving High Fidelity Photo To Video Transformations
The platform follows a rigorous but accessible four-step process to ensure that even users with no prior video editing experience can achieve professional results.
- Step 1: File Preparation. Upload your target image in JPEG, PNG, or JPG format. Ensure the image is clear and well-lit, as the AI uses these details to generate textures.
- Step 2: Motion Description. Use natural language to define how you want the image to come alive. You might describe movement like “gentle waves crashing against the rocks with a 4K cinematic texture.”
- Step 3: Processing Phase. The system’s advanced engines, including Veo and Seedance, begin synthesizing the frames. This process typically lasts about 5 minutes.
- Step 4: Finalization. Once the status reads “Completed,” you can review the motion. If it meets your standards, you can download the final MP4 file for distribution.
Comparative Technical Matrix: Generative Synthesis vs. Traditional Methods
A comparison of features helps to clarify why generative motion is becoming the preferred choice for agile content teams.
| Creative Feature | Traditional Video Editing | Generative AI Platform |
| Asset Requirement | Multiple Video Takes | Single Static Image |
| Motion Control | Manual Keyframing / Tracking | Natural Language + Motion Sliders |
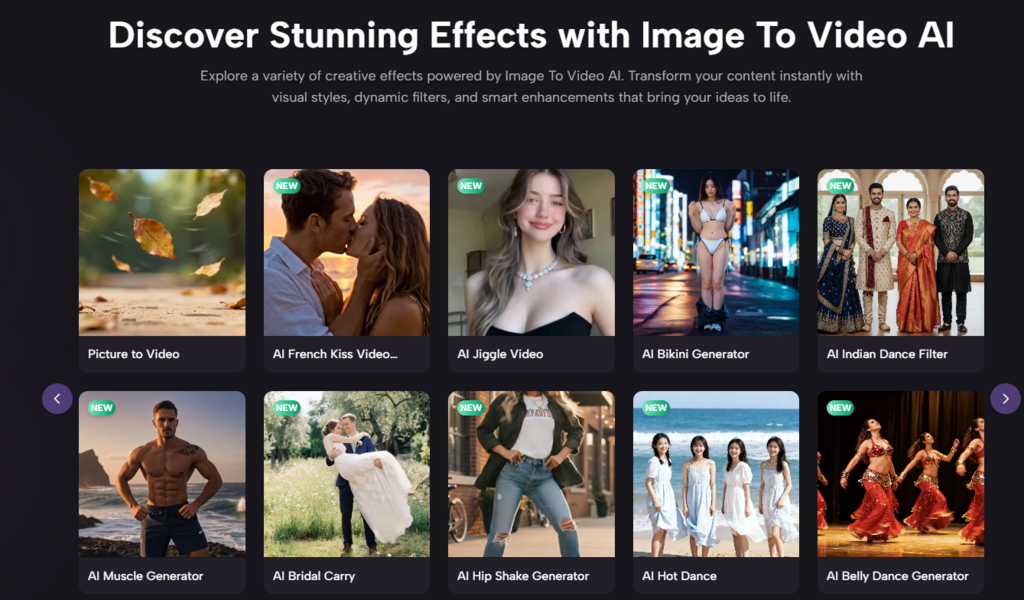
| Specialized Effects | Manual Plugin Application | AI-Driven (Kiss, Hug, Fight, etc.) |
| Restoration Ability | Complex Frame-by-Frame Repair | Automated “Animate Old Photos” Feature |
The versatility of a Photo to Video tool is particularly evident when working with historical or personal archives. The ability to “Animate Old Photos” using specialized restoration algorithms allows for a level of emotional connection that was previously impossible. In my testing, this feature is excellent for bringing life back to family memories or historical documents, as the AI can intelligently guess how a person might have smiled or moved based on the structure of their face in the original still.
Strategic Implementation Of Generative Motion In Modern Marketing
Integrating generative video into a broader content strategy requires a shift toward “high-frequency storytelling.” Because the cost and time barrier is so low, brands can now afford to create bespoke video content for every single social media post, rather than relying on a few “hero” videos per year. This allows for a much more dynamic presence on platforms like TikTok and Instagram, where the algorithm favors fresh, engaging motion content. In my observation, the most successful brands are those that use these tools to create “micro-moments”—short, five-second clips that convey a single mood or product feature with high intensity.
As we look toward the future, the development of models like Sora and Veo 3 will likely extend the duration and complexity of these generations. However, the core principle remains the same: the technology is a multiplier for human creativity. While the AI handles the complex math of motion and physics, the creator provides the vision and the context. By mastering the current tools and understanding their operational flow, creators can build a sustainable workflow that scales with the rapid advancements of the generative AI industry, ensuring their stories are always moving forward.